

Streaming Data Pipeline Using Confluent Cloud and Dataproc on GCP




Photo by Hunter Harritt on Unsplash
Introduction
In This Article, we'll look into How we can build a streaming data pipeline using Confluent Kafka and Spark Structured Streaming on Dataproc(GCP).
Objective: Create a Confluent Kafka Topic and Stream events from Kafka to Google cloud storage bucket using Dataproc and Spark Structured Streaming

Confluent Kafka
Confluent Kafka is a Cloud Native and Fully managed version of Apache Kafka which is widely used for Event Streaming. It is available on major cloud providers i.e., GCP, AWS and Azure.
Features of Confluent Kafka:
Serverless
Secure
Scalable
resilient
It has many other features like Shema Registry, Ksql, Streams, Connectors etc. Explore Confluent.
Spark Structured Streaming
Spark Structured Streaming enables processing data in near real time using the capabailities of DataFrame API. It is built on top of Spark SQL engine, allowing to transform data pretty much same as we do with Batch Data.
Step -1:
Creating Confluent Kafka Cluster and Kafka topic, Confluent Kafka can be launched in two different ways:
- Google Cloud Marketplace
Confluent Platform
Go to Confluent Cloud and create a free account($400 free credit)
Create Environment

Choose Cloud Provider:
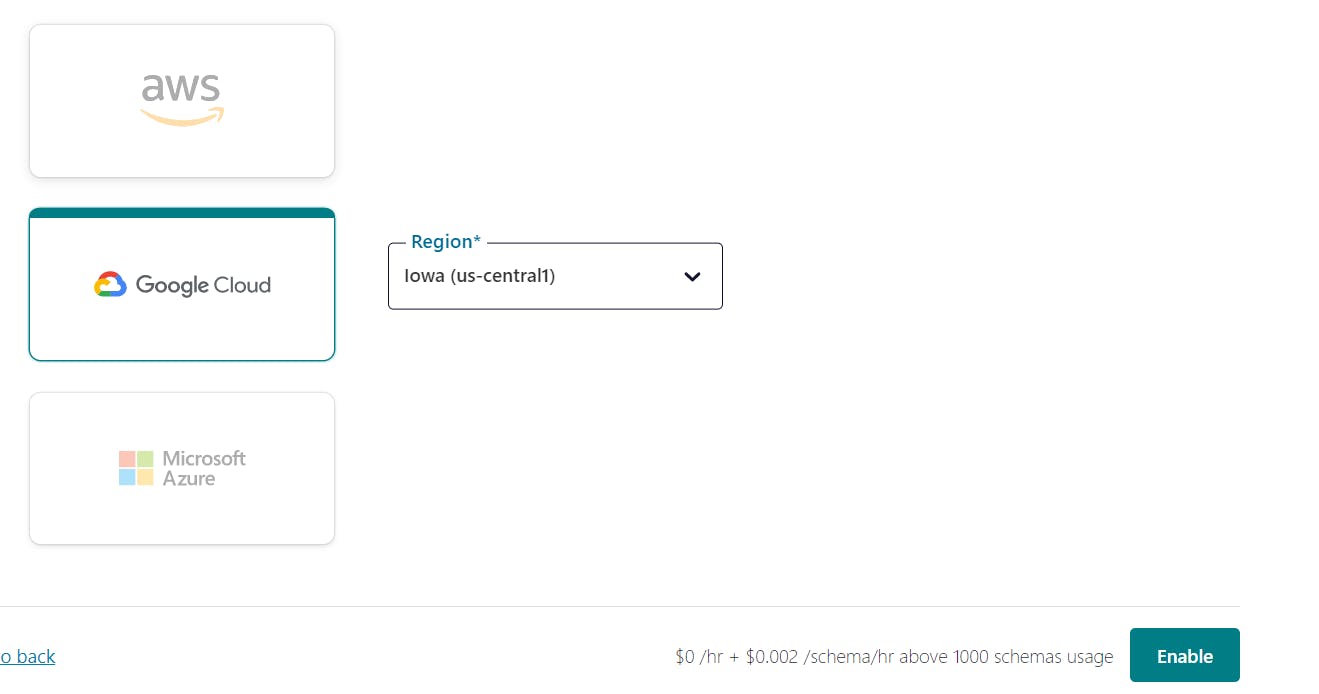
then enable the environment
Create Conflent Cluster
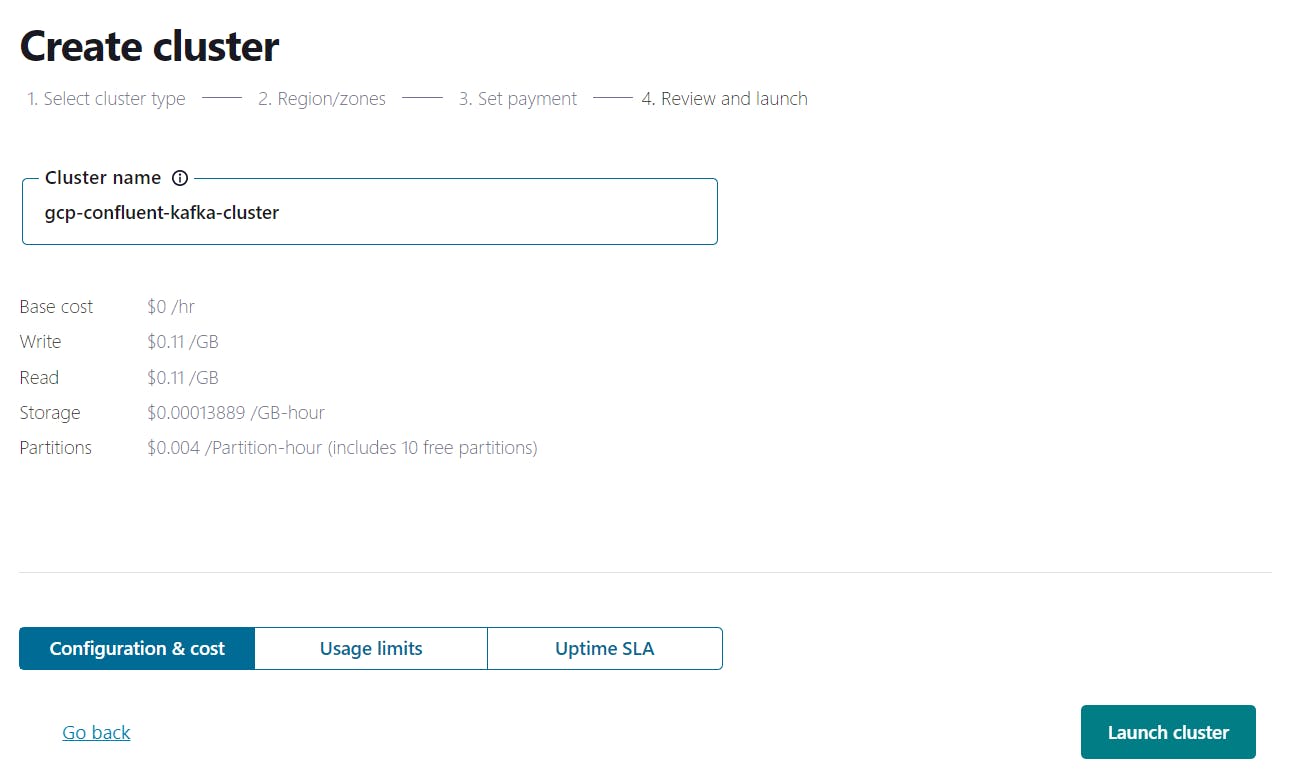
Create the Kafka Topic

Create a API Key, by configuring a Client

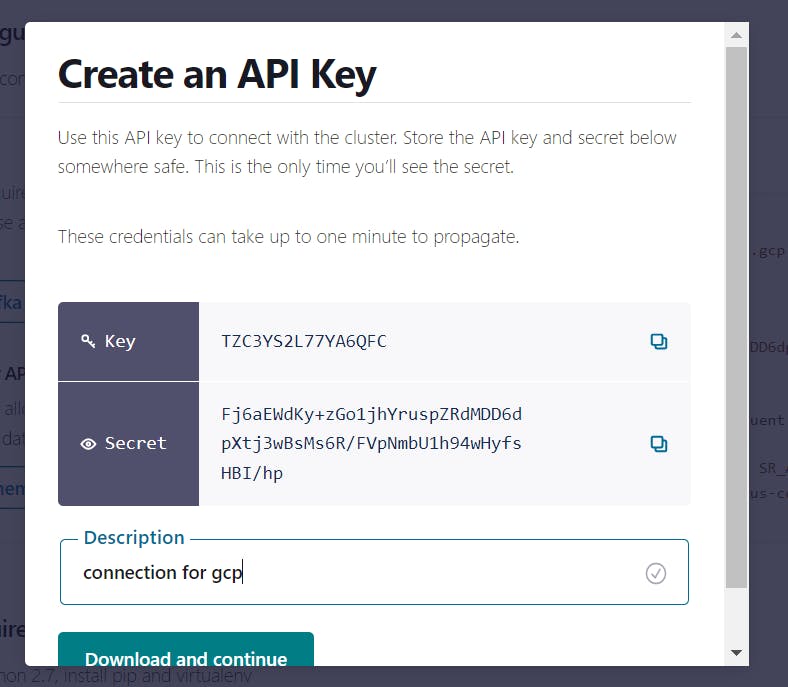
Step-2:
Create Cloud Storage Bucket and Dataproc Cluster.
Step-3:
Creating the PySpark Streaming Job
Configure Kafka properties
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
#kafka params
#it's not good practice to hardcode kafka_APIKey,kafka_APISecret in code, instead use GCP Secret Manager
kafka_broker="your-bootstrap-kafka-server-id"
kafka_APIKey="###########"
kafka_APISecret="###########"
kafka_Topic="your-topic"
checkpoint_GCSUri="gs://your-bucket/tmp/"
create spark session
spark = SparkSession \
.builder \
.appName("confluent-consumer") \
.config("spark.sql.adaptive.enabled", False)\
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.config("spark.sql.streaming.schemaInference", "true") \
.getOrCreate()
Read From Kafka
kafka_Jaas_Config="org.apache.kafka.common.security.plain.PlainLoginModule required username=\"" + kafka_APIKey + "\" password=\"" + kafka_APISecret + "\";"
FromKafkadf = spark.readStream.format("kafka") \
.option("kafka.bootstrap.servers", kafka_broker) \
.option("subscribe", kafka_Topic) \
.option("kafka.security.protocol", "SASL_SSL") \
.option("kafka.sasl.mechanism", "PLAIN") \
.option("kafka.sasl.jaas.config", kafka_Jaas_Config) \
.option("startingOffsets", "earliest") \
.load()
Decode Kafka Message
def decode_kafka_message(clmn):
import base64
return clmn.decode("utf-8")
decode_udf = udf(lambda x: decode_kafka_message(x), StringType())
FromKafkadf = FromKafkadf.withColumn("key",decode_udf(col("key")))
FromKafkadf = FromKafkadf.withColumn("value",decode_udf(col("value")))
Write to GCS
writeToGCS=FromKafkadf.writeStream.format("json")\
.option("checkpointLocation", checkpoint_GCSUri)\
.outputMode("append")\
.option("path","gs://your-bucket/"+kafka_Topic+"/")\
.start()
writeToGCS.awaitTermination()
Now Produce messages into Kafka Topic and run your Streaming Job on Dataproc
Step-4:
Submit Spark streaming job on dataproc cluster, Please note the we need below jar files for successful connection between dataproc and confluent kafka.
JARS Required:
kafka-clients-3.1.0.jar
spark-sql-kafka-0-10_2.12-3.1.0.jar
commons-pool2-2.8.0.jar
spark-streaming-kafka-0-10-assembly_2.12-3.1.0.jar
spark-token-provider-kafka-0-10_2.12-3.1.0.jar
Note: Make Sure the JAR files version and Kafka version are Same.
Output:
Dataproc Job:

Confluent Kafka:

GCS:

Hope this Article will be Helpful for your Streaming Journey. Happy Learning!
Streaming.Stop() :)